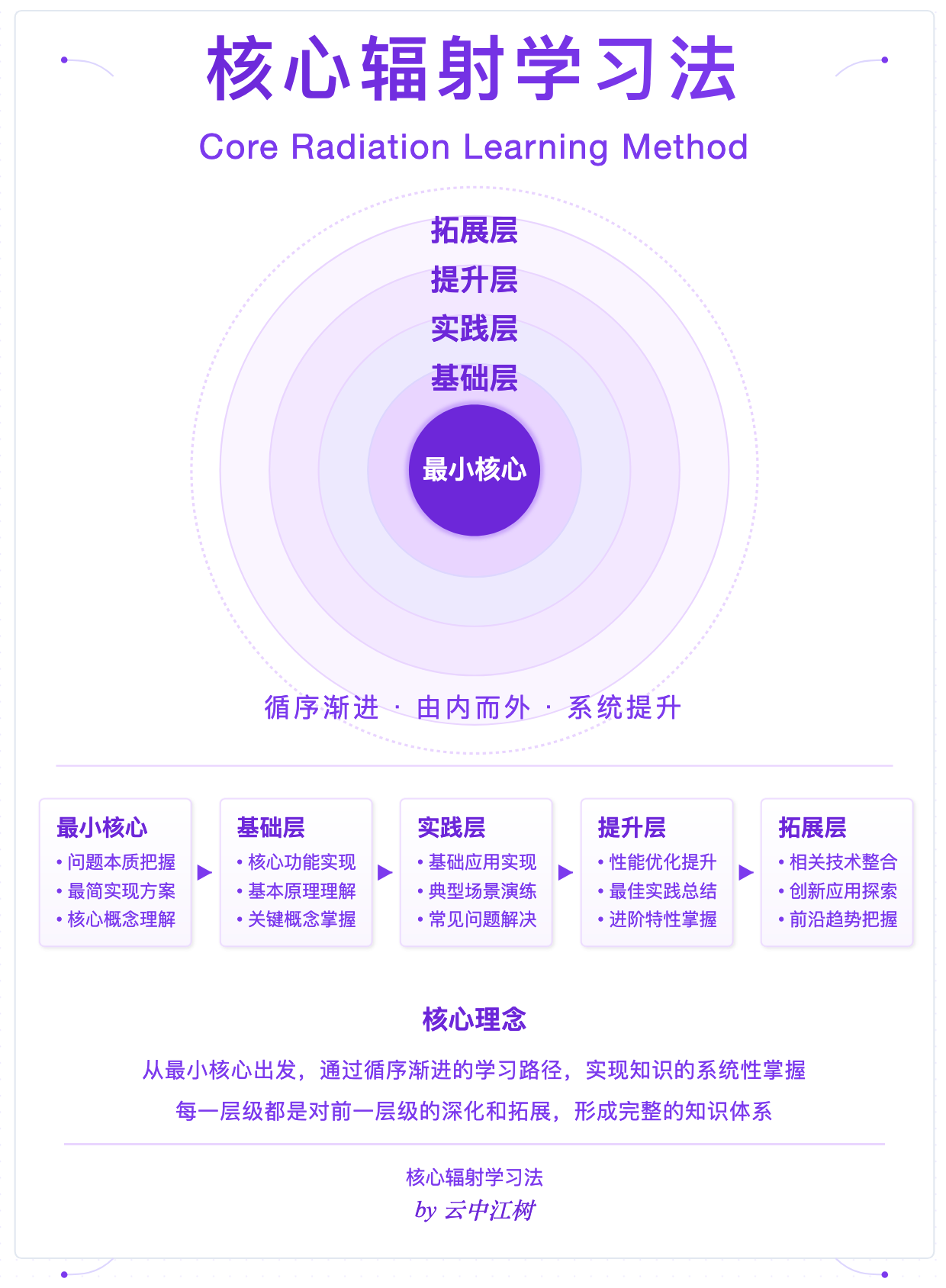
这是我常用的一种学习和思考方法。
学习一项新知识,新技术的时候。如果直接面对一整个庞大的系统性知识,容易产生畏难心理、记忆负担、认知迷茫等问题,同时容易陷入知其然不知其所以然的地步。
为了让自己更快更深的理解掌握一项新知识,我会希望尽可能的抛弃掉所有的复杂性,先从最小核心出发,再慢慢掌握基础,然后实践,然后提升,然后拓展。
以 RAG为例 (个人不专业的回答,欢迎批评指正):
1. 最小核心: 知识 + 指令 构成的提示词。 最简单的做法就是我们读文献的时候,手动将知识复制粘贴给AI (人工检索知识),然后要求AI 根据知识回答问题。
2. 基础层。人工检索效率低,所以最小核心的人工检索知识变为机器检索知识。
知识太多,无法一次输入,所以需要对知识进行分片,于是有了知识切片的各种方法。
为了检索的准,于是有了关键词检索,语义检索等技术。
为了进行语义检索,需要将文字转换为向量,所以有了转换的embedding 模型,要对这些向量操作,所以需要向量数据库。
机器将检索到的知识和指令结合构成提示词,引导模型生成回答。
3. 实践层。基本上使用上面这些就能构建一个小的rag系统,花时间实验,试错,调优。在优化的过程中发现更多问题,检索不准的问题,生成不理想的问题等等。
4. 提升层。为了优化检索效果,检索的时候使用各种混合方法,有些问题依赖的知识分布在多段内容中,因此使用多段内容。但是这些内容和问题直接的相关性等又有不同,希望筛选出最相关的,于是有了对检索得到的知识的排序,有了排序模型。为了进一步提升系统效果,使用更好的模型,更好的参数,对生成数据流优化,各个步骤上的参数测试优化等等。
5. 拓展层。进一步进行系统层面的优化,对系统稳定性,易用性,产品设计等方面优化。比如在实际使用过程中发现很多问题是重复的,这时候就可以构建缓存系统,第一次回答之后下次类似问题进来直接使用缓存的已有答案。
思考是这个核心辐射的逆过程,不断剔除掉外在的复杂性,观察事物是否成立,最后只保留下最小的不可去除的核心。
个人按这个思路,Agent 和 RAG 如果不断去除掉复杂性,最终保留到最小核心的话,可以回退到 prompt 的构造法。
转载请注明:乐无限,互联网有趣资源聚合地 » 核心辐射学习法